
We introduce FinDER, a benchmark developed by LinqAlpha to evaluate retrieval systems on realistic, ambiguous financial questions. Results show that our domain-adapted semantic retriever significantly outperforms strong baselines, proving the value of finance-specific fine-tuning for RAG.
Building Institutional-Ready Financial QA System.
Part 2: Semantic Retrieval on FinDER
In Part 1, we showed that finance-specialized retrieval systems like LinqAlpha’s outperform general-purpose approaches on FinanceBench, a public benchmark for structured financial QA. However, FinanceBench questions are relatively explicit and well-structured. Real-world financial questions are often shorter, more ambiguous, and full of domain-specific shorthand.
Accurately answering such questions requires more than just document retrieval. It requires advanced interpretive ability and deep domain-specific contextual understanding. To address this challenge, LinqAlpha developed FinDER (Financial Domain Expert Retrieval), the first benchmark designed to reflect the ambiguity and complexity of real analyst workflows. The dataset is also available on Hugging Face. Alongside the dataset, we built a domain-specific semantic retriever fine-tuned to handle these realistic query patterns.
Task: FinDER, a Realistic and Ambiguity-Aware Financial RAG Benchmark
FinDER is the first retrieval-augmented generation (RAG) benchmark purpose-built for financial QA. We designed it to evaluate retrieval and generation capabilities in scenarios that replicate actual analyst workflows. The dataset contains 10-K filings, questions, answers, and expert-annotated evidence for a total of 5,703 query–evidence–answer triplets.
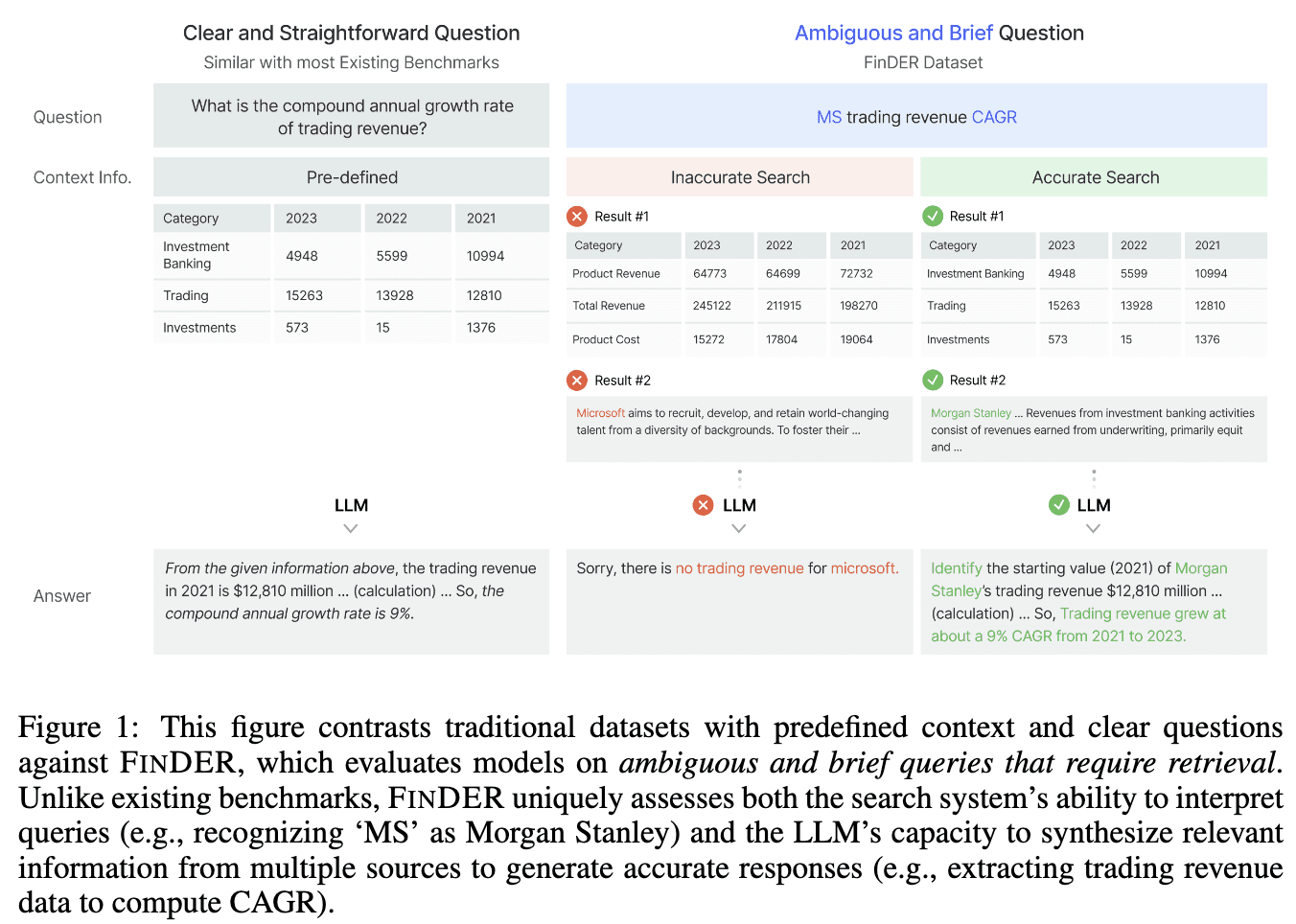
As shown in Figure 1, FinDER questions often include domain-specific expressions such as abbreviations, jargon, and company short forms (e.g., “MS” for Morgan Stanley). They are concise yet require interpretation before retrieval. Systems must correctly identify the intended entity or metric, then gather multiple pieces of evidence to perform calculations or reasoning.
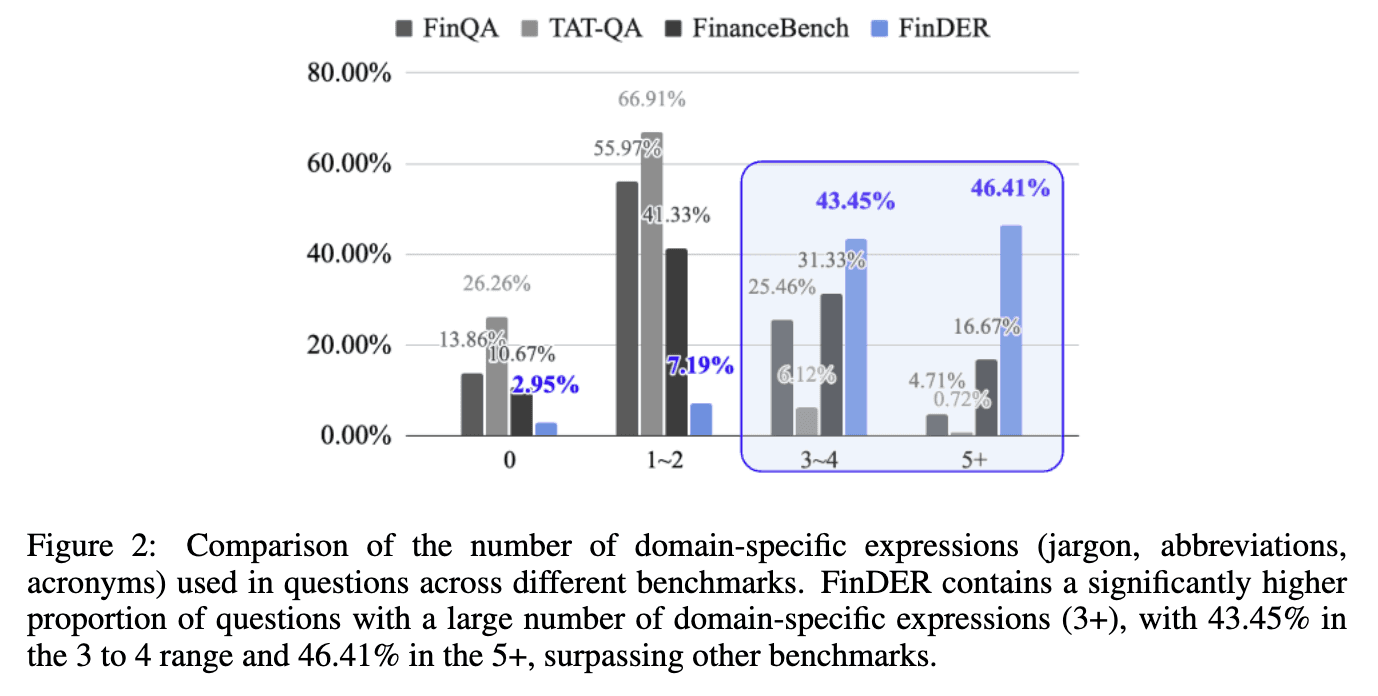
As illustrated in Figure 2, other benchmarks rarely include finance-specific terminology. FinDER’s key distinction is its faithful reflection of how domain experts ask questions and navigate filings.

As shown in Table 1, topics span company overviews, financial statements, notes, and governance.

Table 2 and Table 3 indicate that 84.5% of questions are qualitative, while 15.5% are quantitative. About half of the quantitative set requires complex, multi-step reasoning. In other words, FinDER replicates real-world scenarios where information is scattered across multiple sections.
Results on Retrieval Performance
RAG consists of two main stages: retrieval and generation. The quality of retrieved content sets the ceiling for generation quality. To evaluate retrieval performance on realistic queries, we compared LinqAlpha’s retriever against several strong baselines: traditional sparse methods like BM25 and dense retrievers such as GTE, mE5, and E5-Mistral.
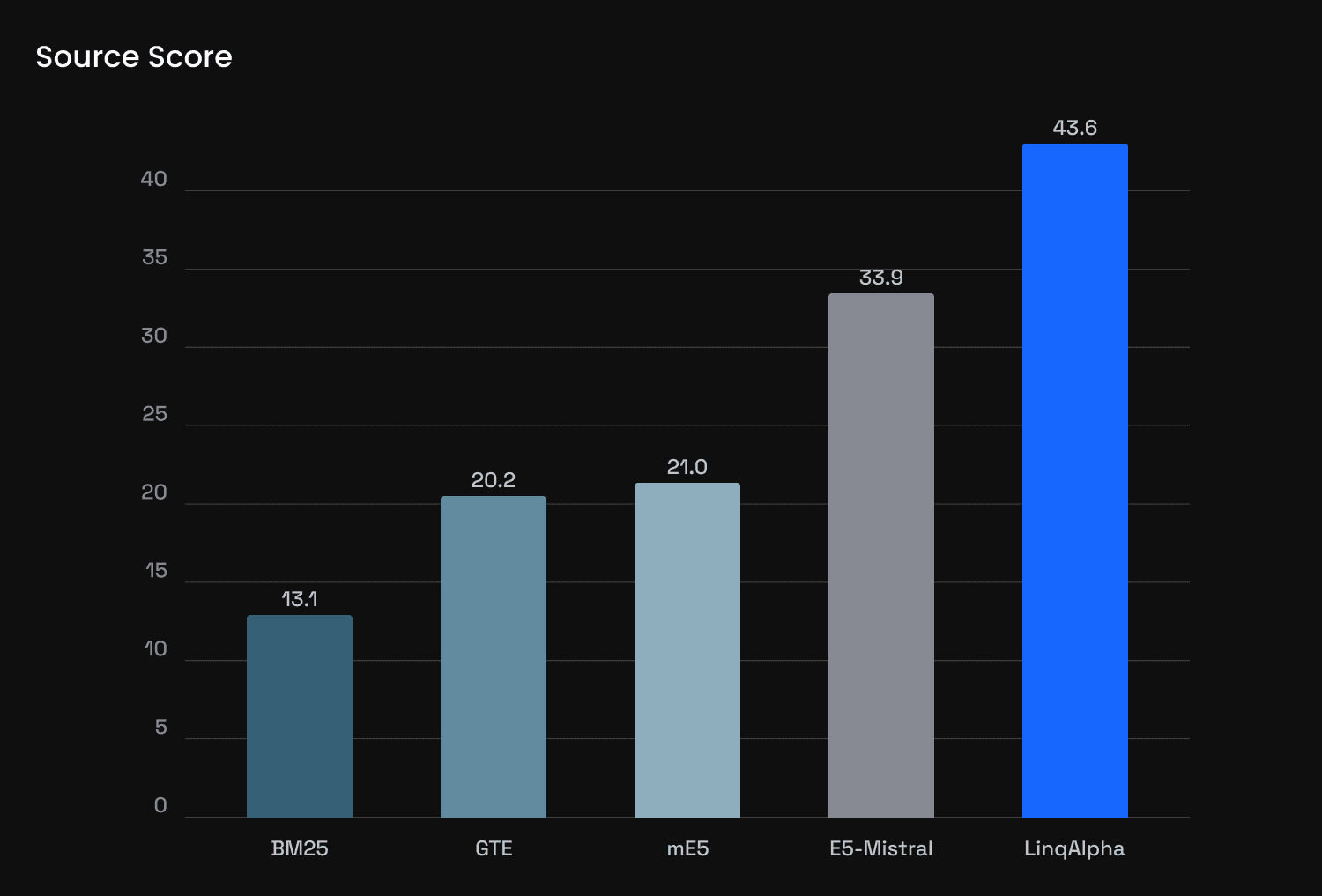
The chart above shows the proportion of top-10 retrieved sources that are actually relevant. LinqAlpha’s retriever outperforms all baselines by more than 10 percentage points over the strongest competitor (E5-Mistral). This gain comes from domain adaptation, where the model was fine-tuned specifically for FinDER-style ambiguous queries. Since RAG answer quality is highly dependent on the relevance of retrieved evidence, these gains directly improve end-to-end QA accuracy.
Conclusion
FinDER was built to capture the ambiguity and complexity of real-world financial questions. Our experiments show that LinqAlpha’s domain-adapted semantic retriever consistently outperforms strong baselines, highlighting the value of tailoring retrieval models to realistic, domain-heavy queries.
What’s Next
Even the best semantic retrievers can fail when questions require multi-step reasoning. In Part 3, we introduce FinAgentBench, our benchmark for agentic retrieval, which incorporates domain reasoning directly into the retrieval process. This approach mirrors how analysts decide which document to open first and where within it to find the answer.