
We evaluate LinqAlpha’s financial QA system on FinanceBench, a public benchmark for question answering over SEC filings and earnings reports. Results show that purpose-built retrieval for finance delivers substantially higher accuracy and more reliable sourcing than general-purpose, web-search-based approaches.
Building Institutional-Ready Financial QA System.
Part 1: Why Retrieval Matters for Accuracy
Today’s financial information is packed with complex numbers, technical terms, and subtle disclosures, making even simple questions surprisingly difficult to answer accurately. Traditional search systems often fall short. What is needed is an expert-level system that delivers responses grounded in verifiable data and structured analytical reasoning.
At LinqAlpha, we have been focused on solving this problem in the context of financial question answering (QA). This blog series shares the motivations, experiments, and insights that have shaped our approach. In this first post, we analyze performance differences across models using FinanceBench, a public benchmark for financial QA that we did not develop, and explore why LinqAlpha’s system stands out in terms of accuracy and source-grounded responses. Future posts will cover questions that require more complex context and domain expertise, as well as evaluations of advanced retrieval and reasoning capabilities. Through this, we aim to define the essential qualities of a truly finance-specialized QA system.
Task: FinanceBench, a Conventional Benchmark in Finance

FinanceBench quantitatively evaluates the performance of large language models (LLMs) on financial QA tasks. Unlike simple fact retrieval, this benchmark focuses on scenarios that reflect real-world workflows, combining document-based retrieval with numerical and logical reasoning as shown above. The dataset is built from 361 public filings including 10-K, 10-Q, 8-K, and earnings reports, spanning 40 publicly listed US companies. From these, it constructs 10,231 question–answer–evidence triplets, of which 150 questions have been publicly released for evaluation.
The benchmark covers three types of questions. First, domain-relevant questions that apply broadly across companies, such as whether a firm paid dividends last year or whether margins were consistent. Second, novel generated questions tailored to the specific company, sector, and context, reflecting more realistic analyst tasks. Third, metrics-generated questions that require extracting or calculating key financial indicators from statements, such as computing ROA. LinqAlpha’s system was benchmarked alongside GPT-4o with search, GPT-o3, and Perplexity using a filtered set of 144 questions, excluding those without a specified company or fiscal year. All responses were manually reviewed and labeled as correct, incorrect, or unanswerable, with evaluation considering answer accuracy, reasoning validity, and source attribution.
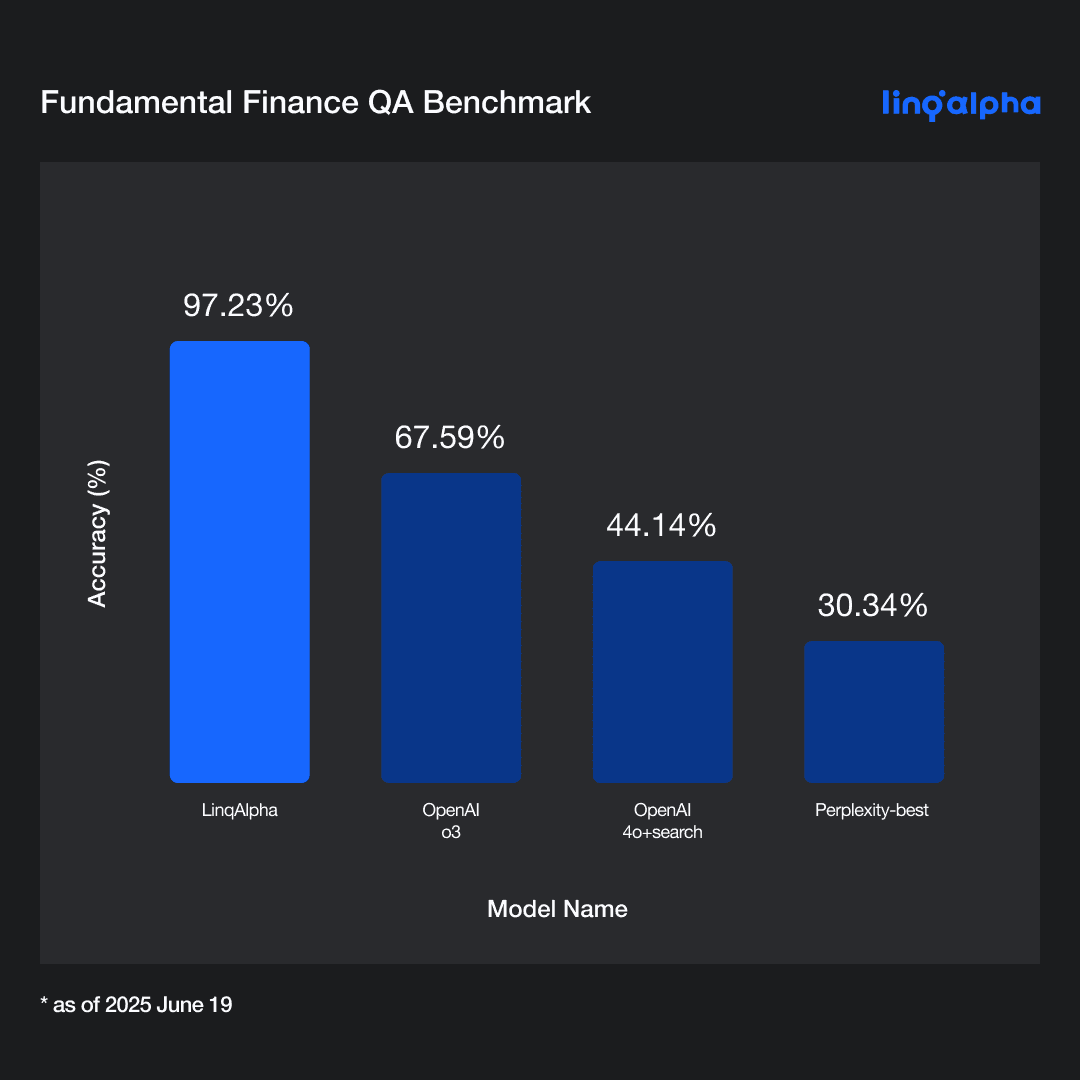
Quantitative Result - Overall Accuracy
Based on 144 financial questions from FinanceBench, the table above shows that LinqAlpha achieves 97.23% accuracy, significantly higher than other models. The key difference lies in retrieval: LinqAlpha uses a system tailored for financial documents, while others rely on general web search. The large performance gap suggests that web search alone is insufficient for accurate financial QA. Even advanced models like OpenAI’s o3 and 4o+search produced incorrect answers for more than 3 out of 10 questions. These results highlight the importance of grounded, document-based QA systems over general-purpose retrieval.
Quantitative Result - Response Comparison
LinqAlpha achieved over 97% accuracy on FinanceBench, showing a clear performance gap compared to general-purpose models. However, accuracy alone does not fully explain the differences. In financial QA, where numerical reasoning and complex document interpretation are essential, how an answer is derived matters as much as whether it is correct. We compared responses from LinqAlpha and OpenAI’s o3 to see why the gap exists.
LinqAlpha consistently grounds outputs in authoritative primary sources, such as SEC filings, and performs structured reasoning based on accounting definitions. In contrast, o3 often makes calculation errors or relies on third-party aggregators that provide estimated or incomplete figures. The examples below show that true reliability in financial QA requires more than high accuracy. It requires verifiable sources and rigorous analytical logic.
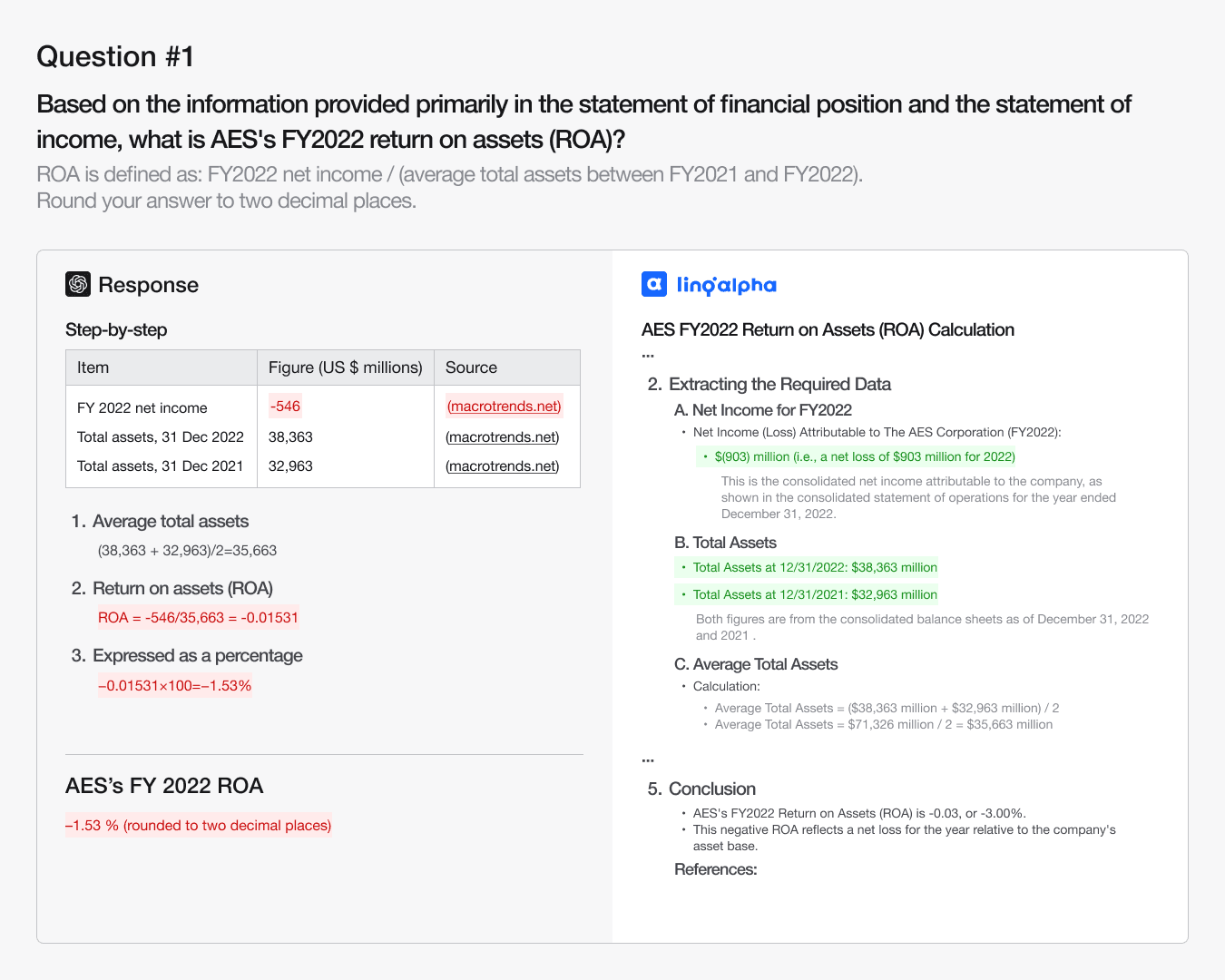



For example, in Question #1 (Amcor, changes in provisions), LinqAlpha cited the relevant section from the company’s 10-K and outlined year-over-year changes based on primary source data. o3 used an unrelated external charting site and produced an incorrect figure. In Question #3 (AES, ROA calculation), LinqAlpha identified the correct revenue and asset values from filings and computed ROA step-by-step based on accounting definitions. o3 misapplied the formula, gave vague numerator/denominator logic, and used inconsistent figures. The key differentiators are not just correctness but the quality of justification.
Conclusion
These differences appear consistently across many questions. LinqAlpha’s advantage lies in both model performance and its retrieval system designed for financial documents, combined with a structured approach to reasoning. In professional settings, the reliability of a response depends as much on its source and explanation as on the final number, something general-purpose, web-search-based QA systems often fail to deliver. This comparison goes beyond accuracy metrics and provides concrete evidence for why LinqAlpha is a more trustworthy system for financial QA.
What’s Next?
In this post, we explored FinanceBench, a relatively structured benchmark, and showed that strong performance in financial QA depends not only on a model’s capabilities but on how effectively it retrieves and grounds answers in reliable sources. In real-world settings, financial questions are often ambiguous and brief rather than clearly structured. Experts often ask concise, context-heavy questions that require high levels of interpretation and domain knowledge. Solving 150 well-crafted questions is not enough to evaluate a system’s ability to handle such challenges. That is why we developed FinDER, a benchmark designed to reflect more realistic and complex queries. In the next post, we will introduce FinDER in detail, explain how it tests a model’s ability to interpret vague, domain-heavy questions, and discuss its implications for building robust financial QA systems.