
We fine-tuned GPT-4o-mini to power a two-stage retrieval system that mirrors how analysts actually work first selecting the right document type, then extracting the most relevant chunks. This model now supports basic search, deep research, and other research workflows.
At LinqAlpha, we recently deployed a fine-tuned GPT-4o-mini model to serve as the core reasoning engine for our agentic retrieval system. The LLM model supports two distinct steps:
Document-Type Selection: Identify the most relevant SEC filing type (10-K, 10-Q, 8-K, earnings call, DEF14A) based on user query intent
Chunk Ranking: Within the selected document, rank paragraphs by likelihood of containing the correct answer
This two-step pipeline is now live in production across workflows used by over 170 institutional investors across investment banking, asset management, and hedge funds.
Why Agentic Retrieval
Institutional research questions often require more than just retrieving semantically similar text—they require structured reasoning.
In financial documents, information is spread across a complex landscape:
Different document types serve different functions (e.g., risk → 10-K, guidance → earnings call, comp → DEF14A)
The same fact may appear in multiple locations—tables, footnotes, boilerplate, Q&A—with varying degrees of clarity or relevance
Context matters, both in structure (e.g., speaker roles, filing sections) and in interpretation (e.g., tone, intent)
Flat retrieval pipelines, whether vector search or hybrid embedding + keyword systems, treat all content equally and apply a single-stage matching process. This leads to:
Relevance errors (e.g., surfacing a table when commentary is expected)
Missed context (e.g., quoting Q&A out of management narrative)
Document-type confusion (e.g., pulling from 10-Q when 8-K contains the actual update)
Agentic retrieval solves this by introducing multi-step reasoning, structured as:
Document-Type Selection
Identify which type of filing is most likely to contain the answer
Chunk Ranking within Selected Document
Search within the chosen document for the most relevant passage
This two-stage pipeline better mirrors how financial analysts actually operate. First, navigating structure, then, extracting signal.
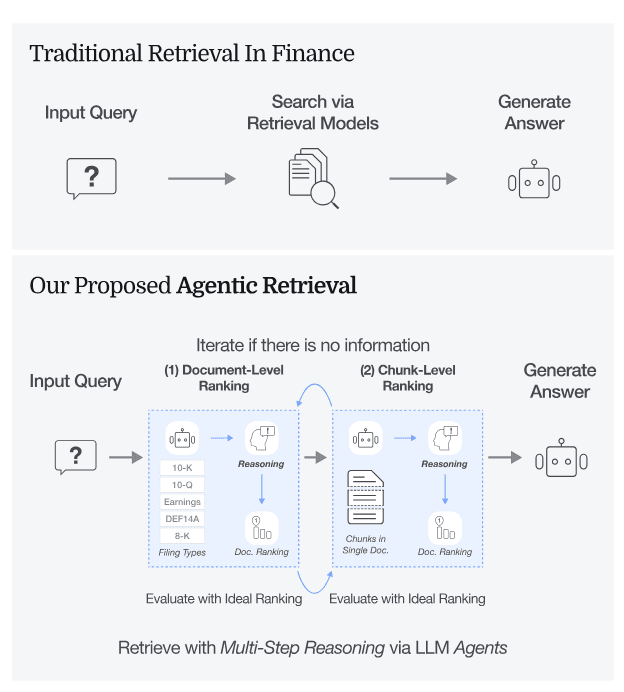
[Figure 1: Agentic vs Traditional Retrieval] Traditional retrieval applies a single-step ranking across all content. Agentic retrieval introduces reasoning over both document structure and content—first selecting the right filing type, then retrieving the most relevant passages inside it.
Why Agentic Retrieval Needs Fine-Tuning
But structure alone isn’t enough. For agentic retrieval to work in practice, the model needs to understand the implicit rules of financial disclosures and research workflows.
Even advanced LLMs don’t inherently know that:
Risk factors are disclosed in Item 1A of 10-Ks
Compensation details appear only in DEF14As
Analysts prefer narrative commentary over footnotes and disclaimers
To bridge this gap, we fine-tuned GPT-4o-mini on a domain-specific corpus with expert-labeled supervision. This training taught the model not just how to retrieve, but how to reason like an human analyst.
Our fine-tuning process embedded:
Disclosure structure priors (e.g., forward-looking statements → earnings, shareholder actions → DEF14A)
Preference signals or Contextual disambiguation
Without fine-tuning, the model treats all document types and formats as interchangeable. With fine-tuning, it learns to make targeted, explainable retrieval decisions that align with real-world research workflows.
What the Model Actually Does
To operationalize agentic retrieval, we formulated the task as two supervised ranking problems, each grounded in domain reasoning.
Task 1: Document-Type Ranking
Input: natural language query
Output: ranked list of document types (e.g., [earnings, 10-K, 8-K, DEF14A, 10-Q])
The model learns structural priors based on institutional workflows:
Risk factors → 10-K
Shareholder votes → DEF14A
Management tone or guidance → earnings calls
Operational updates → 8-K
This stage teaches the model to reason about where answers are most likely to appear. It mirrors the initial routing step an analyst takes before reading.
Task 2: Chunk-Level Ranking
Input: query and top-ranked document
Output: top-k most relevant chunks (paragraphs)
This stage captures fine-grained selection behavior:
Prefers narrative over numerical tables, especially in guidance or sentiment queries
De-prioritizes boilerplate, footnotes, and repeated sections
Disambiguates chunks that reference similar concepts but differ in specificity
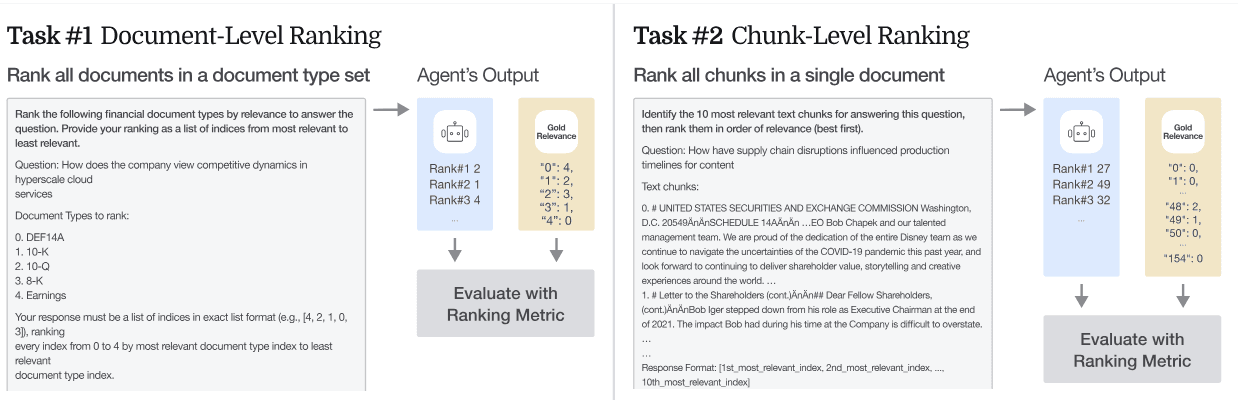
[Figure 2: Task Setup for Ranking] Left panel shows Task 1, where the model ranks SEC document types by relevance to the query. Right panel shows Task 2, where it selects and ranks the most relevant paragraphs from the chosen document.
Training Setup
We fine-tuned GPT-4o-mini using reinforcement learning from human feedback (RFT). The objective was to teach structured reasoning across document formats and reporting conventions, not just simple relevance.
Core Setup
Model: GPT-4o-mini
Fine-tuning objective: document-type and chunk-level ranking
Data source: US public company filings from SEC EDGAR (10-K, 10-Q, 8-K, earnings calls, DEF14A)
Labeling: Expert-annotated with
Task 1: top-1 and ranked document-type labels
Task 2: paragraph-level relevance scored as 0 (irrelevant), 1 (partially relevant), or 2 (directly relevant)
Annotation Design Principles
We incorporated several design choices to better align the model with analyst behavior:
Pecking order among duplicates: When the same information appeared multiple times, we labeled the most useful version. For example, narrative commentary was prioritized over tables and boilerplate.
Probabilistic handling of borderline cases: We included partial relevance grades to reflect how analysts hedge or weigh incomplete information.
Finance-specific query phrasing: Training queries included domain language such as “CUDA moat,” “YoY delta,” or “opex compression,” allowing the model to ground reasoning in real institutional language.
Dataset Summary
Approximately 500 annotated examples
All based on US-listed equities (non-US coverage is underway)
Queries manually written and reviewed by financial professionals
Coverage spans the following query types: analyst Q&A, management commentary, guidance, industry and market, investor sentiment, earnings result or financials, compensation, macro and economics, risks and challenges, operating metrics
Evaluation Results
We evaluated the model on standard ranking metrics: nDCG@5, MAP@5, and MRR@5.
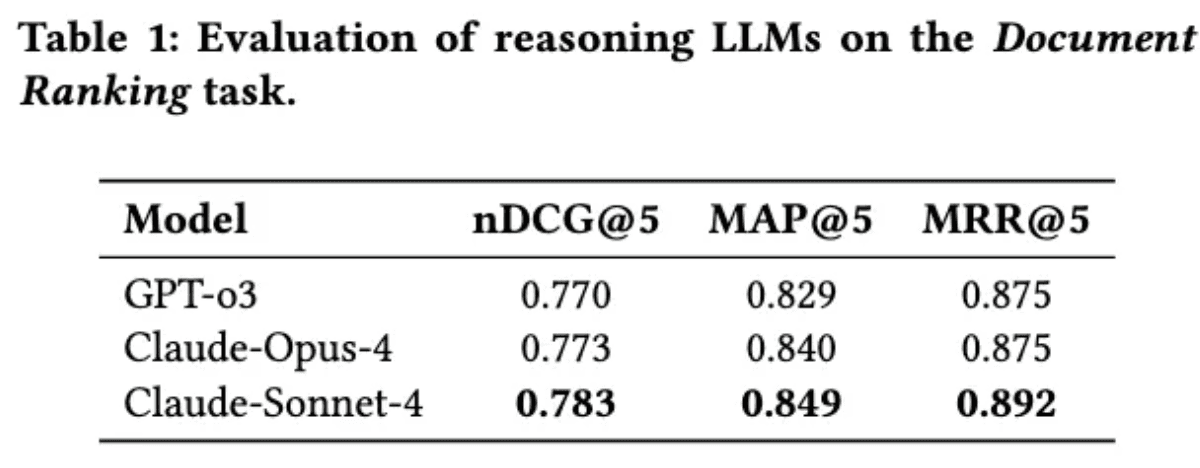
[Table 1: Document Ranking – Zero-shot Baseline] Performance of GPT-3 and Claude models on the document-type ranking task (zero-shot).
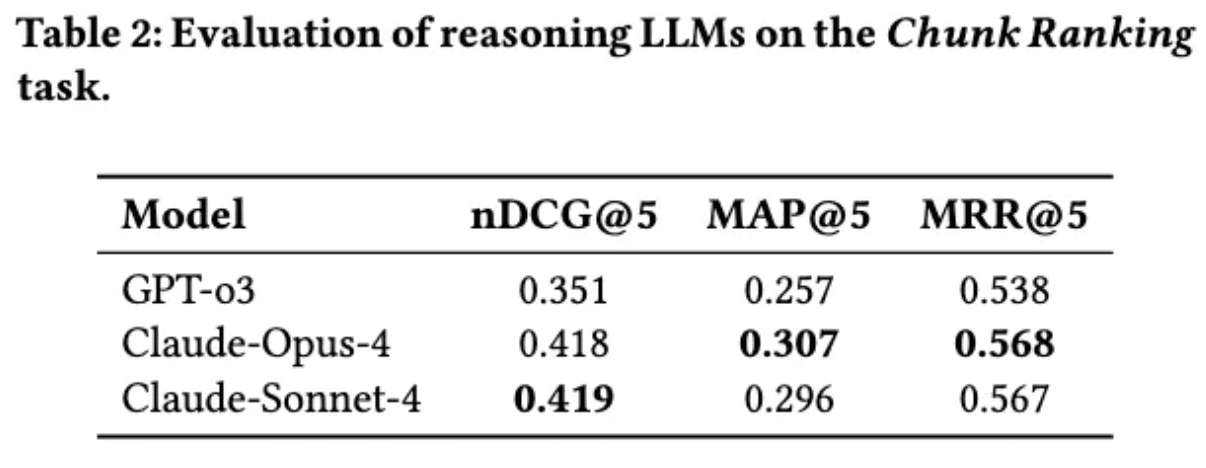
[Table 2: Chunk Ranking – Zero-shot Baseline] Performance of GPT-3 and Claude models on the chunk-level ranking task (zero-shot).

[Table 3: GPT-4o-mini Before and After Fine-Tuning] Fine-tuning GPT-4o-mini with retrieval supervision led to measurable gains across both document and chunk-level ranking tasks.
Summary of Gains
Document Ranking: +6.6% nDCG improvement
Chunk Ranking: +7.5% nDCG improvement
These improvements reduced false positives (e.g., returning GAAP tables when the query is about management sentiment) and improved chunk prioritization across earnings and 10-K documents.
Deployment
The fine-tuned GPT-4o-mini model is now fully integrated into LinqAlpha’s agentic retrieval stack. It powers:
Earnings season Q&A pipelines
Search-and-summarize workflows for guidance and macroeconomic topics
Real-time chunk filtering for both internal tools and client-facing dashboards
What’s Next
We are scaling the system to cover non-US equities and preparing a partial public release of FinAgentBench, a benchmark for evaluating agentic retrieval systems in finance. The release will include:
A subset of 17,000+ annotated institutional-grade queries
Dual-task evaluation across document-level and chunk-level ranking
Prompts written and reviewed by financial analysts across 10 research categories
If you are building retrieval systems for investment research, where document structure, multi-step reasoning, and interpretability are critical, agentic retrieval with a fine-tuned LLM may offer a more effective foundation than traditional RAG pipelines.
For benchmark access or evaluation trials, contact support@linqalpha.com.